Indexes
Intro
An index is a sorted auxiliary structure that helps the SQL engine avoid full table scans for many read queries. In SQL Server, indexes are implemented as B+ trees, so lookup cost grows much slower than row count (O(log n) instead of O(n) for many lookup patterns). The tradeoff is write overhead and extra storage.
When indexes help and when they hurt
- Indexes help when queries filter, join, or sort on selective columns.
- Indexes hurt write-heavy tables because inserts, updates, and deletes also maintain index pages.
- Indexes consume extra disk space; wider keys and many indexes increase storage and memory pressure.
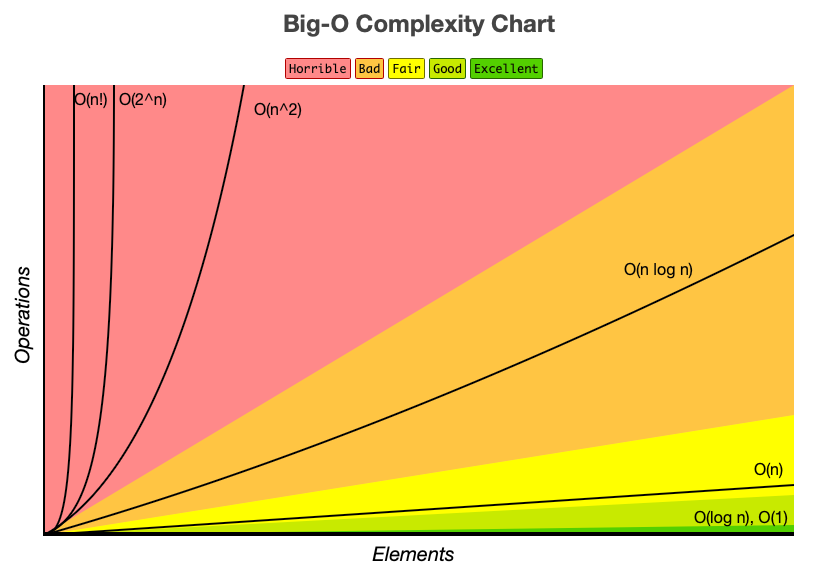
Mental model: how index pages are organized
Heap
A heap is a table without a clustered index. Rows are not kept in key order, so search typically requires scanning pages sequentially.
Index structure
An index is a tree-like, sorted on-disk structure where key values guide navigation to smaller and smaller ranges of data.
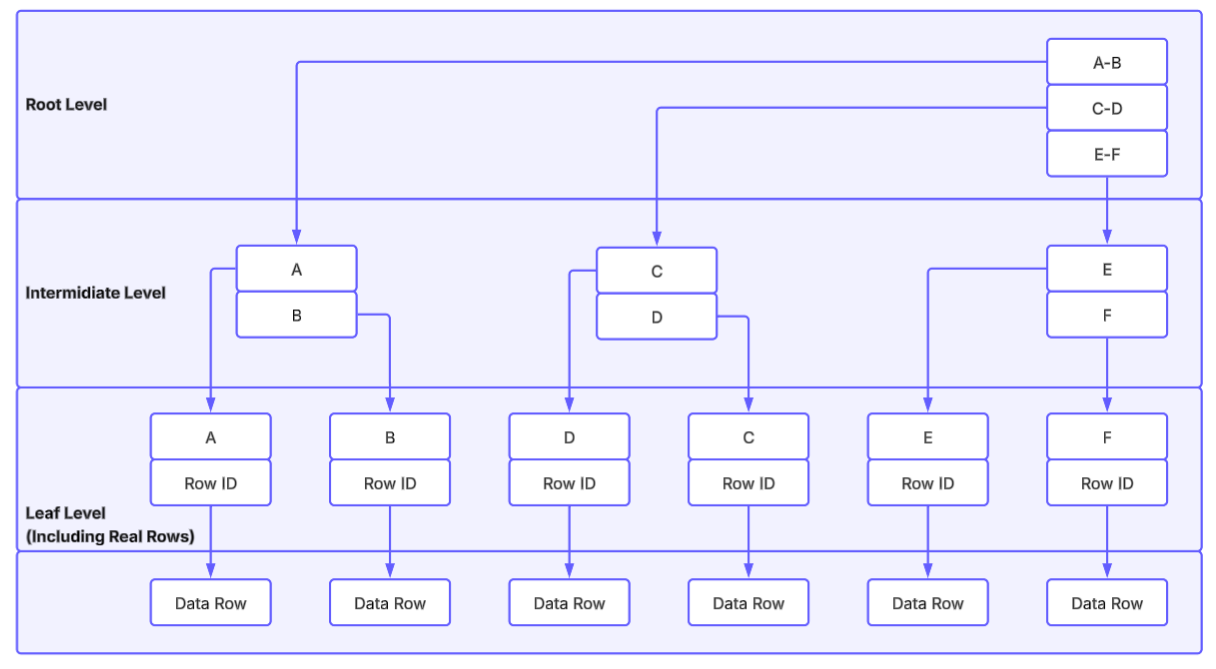
The B+ tree has three logical levels:
- Root node
- Stores key ranges and pointers to intermediate nodes
- Intermediate level
- Stores key ranges and pointers to leaf nodes
- Leaf level
- Contains the final entries for the range (data rows for clustered indexes, row locators for nonclustered indexes)
Clustered index
In a clustered index, leaf pages are the table's real data pages.
- Root rows store key values and pointers to intermediate pages.
- Intermediate rows store key values and pointers further down.
- Pages at each level are linked as a doubly linked list for range scans.
- A table can have only one clustered index because table rows can be physically ordered only one way at a time.
Diagram: Clustered index page hierarchy
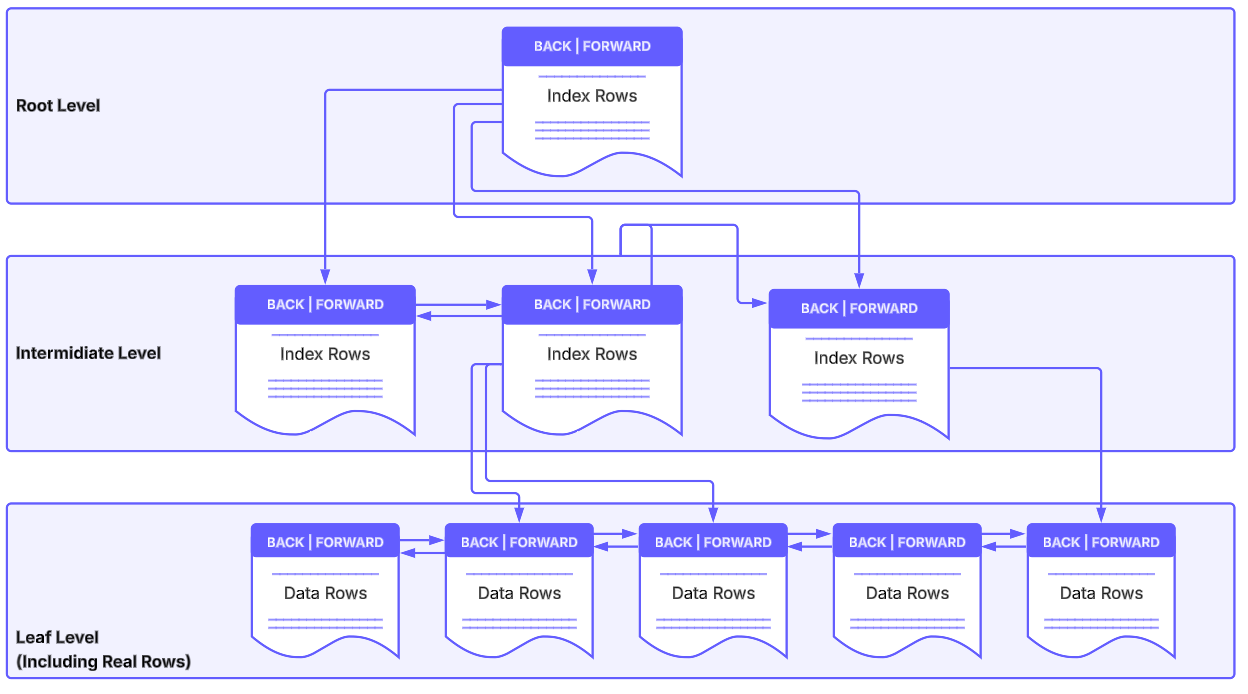
This diagram shows the clustered index B+ tree shape: one root page points to intermediate index pages, and the leaf level contains the actual table rows linked left-to-right for range scans.
Diagram: Clustered index seek path
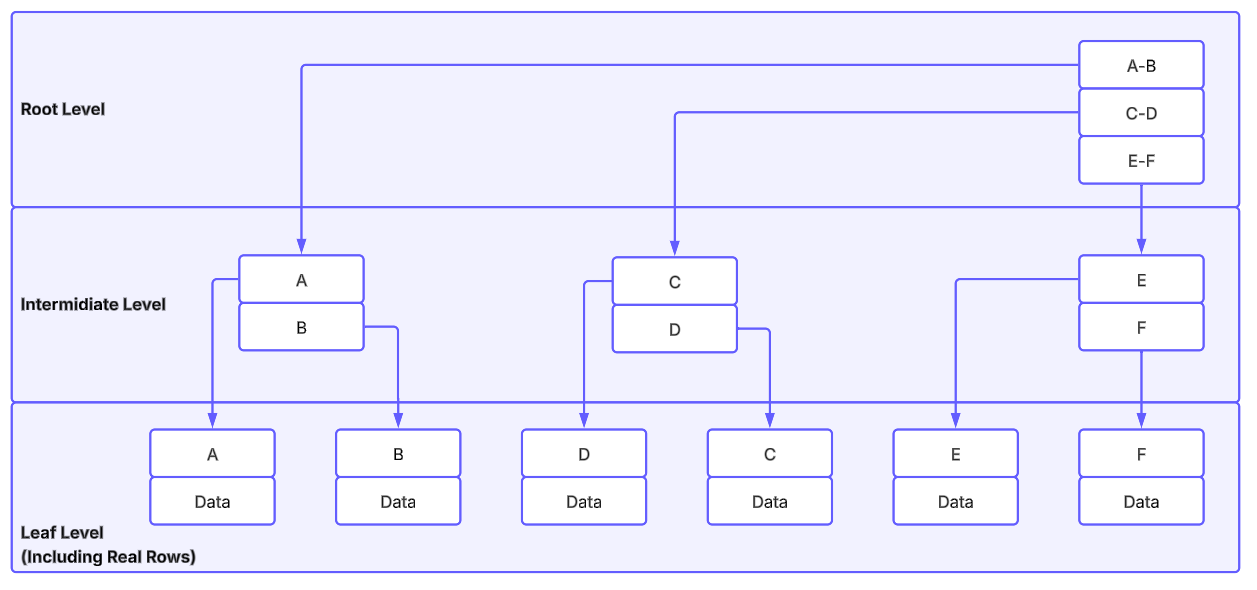
This diagram shows an index seek path through key ranges: the engine starts at the root, chooses the matching intermediate branch, and reaches the leaf page that holds the target row.
Nonclustered index
The leaf level of a nonclustered index stores key columns plus a pointer to actual table data.
With a clustered index on the table
Leaf entries store the clustered key value (key lookup path).
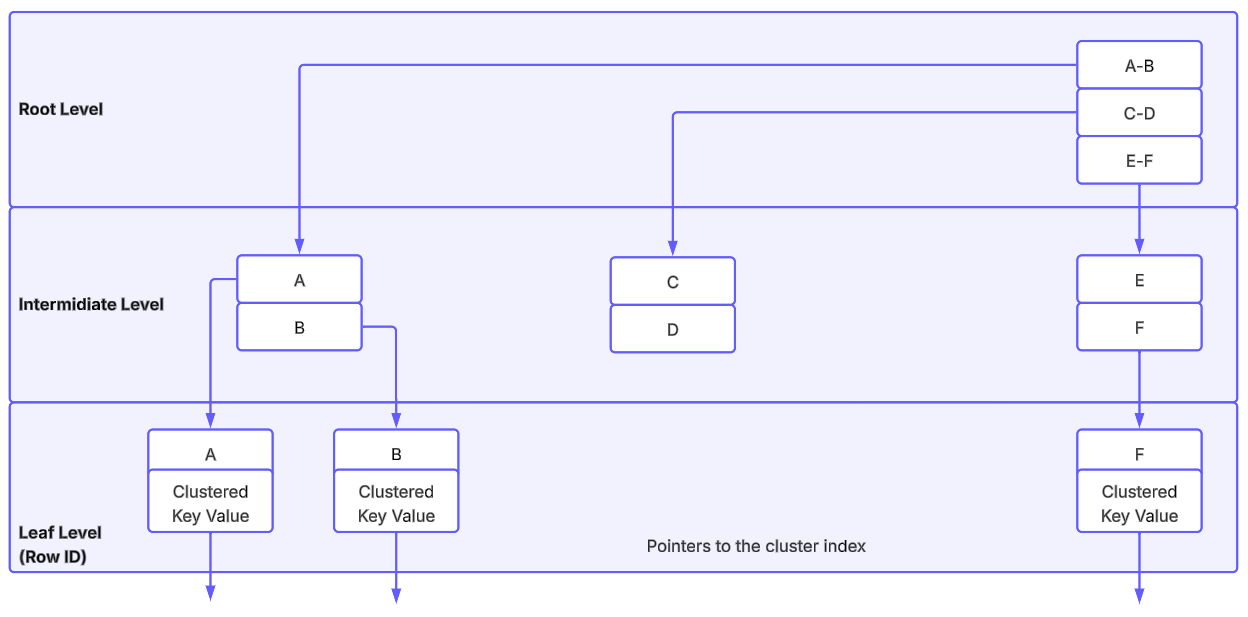
Without a clustered index (heap)
Leaf entries store a row identifier (RID): file, page, and slot location.
Simplified seek example
Assume a clustered index on ID with values from 1 to 5000. We need ID = 1456.
- At the root, pick the branch for
1251..2500. - In that intermediate page, pick the leaf page for
1251..1500. - Scan inside that leaf page to find
1456.
The search space drops from 5000 rows to one small page range (illustrative page sizing).
Covering Indexes and Included Columns
A covering index satisfies a query entirely from the index without touching the base table. When a nonclustered index seek finds a matching row but the query needs columns not in the index, SQL Server performs a Key Lookup back to the clustered index for each row. On large result sets this becomes expensive fast.
The INCLUDE clause adds columns to the leaf level only, not to the B-tree navigation nodes. This means they don't participate in seeks or ordering, but they're available at the leaf so the engine never needs to follow the key lookup path.
-- Without covering: index seek + key lookup per row for Email and LastLogin
CREATE INDEX IX_Users_Status ON Users (Status);
-- Covering: leaf stores Status (key) + Email + LastLogin (included)
CREATE INDEX IX_Users_Status_Covering
ON Users (Status)
INCLUDE (Email, LastLogin);
Key rules:
- SARGable columns (used in
WHERE,JOIN,GROUP BY,ORDER BY) go in the key. - SELECT-only columns go in
INCLUDE. They bypass the 1700-byte nonclustered key size limit (900-byte for clustered) and the 32-column key limit (SQL Server 2016+). - Eliminating Key Lookups is the primary index tuning lever. Check execution plans for "Key Lookup" operators; each one is a candidate for an INCLUDE column.
Columnstore Indexes
Columnstore indexes store data column-by-column rather than row-by-row, compressed into row groups of up to ~1 million rows each. The engine reads only the columns a query touches, skipping the rest entirely.
Batch execution mode processes rows in groups of up to ~900 at a time rather than one row at a time, which is why columnstore queries on large aggregations are significantly faster than equivalent rowstore queries on the same data.
Two variants:
- Clustered columnstore: the entire table is stored as columnstore. Ideal for data warehouse fact tables where you always aggregate large ranges.
- Nonclustered columnstore: a secondary index on a rowstore table, enabling HTAP (hybrid transactional/analytical) workloads without a separate DW.
Columnstore is not a replacement for B+ tree indexes. OLTP point lookups, small range seeks, and frequent single-row updates still belong on rowstore. Use columnstore when queries scan millions of rows and aggregate.
Filtered Indexes
A filtered index is a nonclustered index with a WHERE predicate. It indexes only the rows matching that predicate.
-- Only index active users; 95% of rows are inactive and irrelevant
CREATE INDEX IX_Users_Active
ON Users (LastLogin, Email)
WHERE IsActive = 1;
Best for: columns with many NULLs (add WHERE Col IS NOT NULL to exclude them from the index), sparse active subsets, or status columns where one value dominates. The index is smaller, cheaper to maintain, and often fits entirely in the buffer pool. The query's WHERE clause must be compatible with the filter predicate for the optimizer to use it.
Index Maintenance
Fragmentation happens when page splits leave pages partially empty or out of logical order. Two metrics matter: logical fragmentation (out-of-order pages) and page density (how full each page is).
On modern SSD and cloud storage, random I/O is cheap, so logical fragmentation has less impact than it did on spinning disks, especially for point lookups. For large range scans, page density still matters: sparse pages mean more I/O to read the same data.
Two maintenance operations:
- REORGANIZE: online, leaf-level only, compacts pages in place. Does not update statistics.
- REBUILD: recreates the index from scratch, updates statistics with a full scan. Can be offline or online (online rebuild availability depends on SQL Server edition and index type; it's supported in Azure SQL Database and SQL Server Enterprise).
The statistics trap: performance often improves after a rebuild not because fragmentation was the problem, but because the implicit FULLSCAN statistics update gave the optimizer accurate cardinality estimates. Before scheduling a rebuild, try UPDATE STATISTICS ... WITH FULLSCAN first. If that fixes the query plan, fragmentation was never the issue.
Fill factor controls how full pages are when an index is built or rebuilt. Only lower it for indexes that suffer frequent page splits, typically GUID or random keys. For sequential keys (identity, date), the default (0 = 100%) is fine.
Tradeoffs
- Benefits: faster lookups, faster ordered reads, better range filtering.
- Costs: slower writes, extra storage, low-selectivity columns often give little benefit.
Design recommendations
- Keep indexes minimal on frequently updated tables.
- Add more indexes on large, read-heavy tables after measuring query plans.
- Prefer short, stable, and selective clustered keys (often the primary key).
- Put high-impact
WHEREcolumns first in composite indexes. - Prefer high-cardinality columns where possible.
- Index computed columns only when expressions are deterministic.
Questions
- An index is an auxiliary on-disk structure (usually a B+ tree) that lets the engine seek to rows without scanning the whole table.
- Common types: clustered, nonclustered, unique, composite, filtered, covering (nonclustered with INCLUDE), and columnstore.
- Clustered defines physical row order; nonclustered is a separate structure with a pointer back to the row.
- Columnstore stores data column-by-column for analytics; rowstore B+ tree is for OLTP.
- Key columns participate in B-tree navigation and are subject to the 1700-byte nonclustered key size limit (900-byte for clustered) and the 32-column key limit (SQL Server 2016+).
- INCLUDE columns live only at the leaf level. They bypass both limits and don't affect seek/sort behavior.
- Rule: SARGable columns (used in
WHERE,JOIN,GROUP BY,ORDER BY) go in the key; SELECT-only columns go in INCLUDE. - The goal is eliminating Key Lookup operators in execution plans. Each lookup is a round-trip to the clustered index per row.
- Rebuilding implicitly runs a FULLSCAN statistics update, giving the optimizer accurate cardinality estimates.
- Stale statistics causing a bad plan is a far more common culprit than fragmentation on SSD/cloud storage.
- Test first: run
UPDATE STATISTICS ... WITH FULLSCANwithout rebuilding. If that fixes the plan, fragmentation was never the issue. - Rebuilding indexes purely for fragmentation on modern storage is often wasted maintenance work and causes unnecessary blocking.
Links
- SQL Server and Azure SQL index architecture and design guide — comprehensive reference covering B-tree internals, fill factor, included columns, and index design principles.
- Clustered and nonclustered indexes described — official explanation of the structural difference between clustered and nonclustered indexes with diagrams.
- Optimize index maintenance to improve query performance — guidance on when to reorganize vs rebuild, fragmentation thresholds, and online vs offline operations.
- Columnstore indexes overview — covers columnar storage, batch mode execution, and when columnstore outperforms rowstore for analytics.
- Use The Index, Luke — The B-Tree — practitioner deep-dive into B-tree structure, leaf nodes, and how the optimizer uses indexes; vendor-neutral.
- The Clustered Index Debate (Kimberly Tripp / SQLskills) — expert analysis of clustered index key selection, GUIDs vs integers, and fragmentation implications.
- Erin Stellato — Index Maintenance Myths (SQLskills) — debunks common misconceptions about fragmentation thresholds and maintenance schedules with real benchmark data.